Итак, давайте начнем с основ. Для автоматизированного тестирования мы используем Selenium WebDriver - драйвер, позволяющий писать программы для управления действиями web браузера (Firefox, Chrome и т.д.) Взаимодействие с web драйвером выполняется путём обращения к нему некоторыми методами, определяющими его действие. Например:
findElement - (поиск элемента на странице)
click - (клик по выбранному элементу)
sendKeys - (ввод данных в поле для ввода текста)
select - (выбор значения из выпадающего списка)
Когда мы делаем клик мышкой, вводим текст и выполняем прочие действия на странице - мы эти действия выполняете над вполне конкретным объектом. Selenium WebDriver поступает так же, но поскольку он не умеет читать наши мысли, то ему надо четко указать объект, для которого необходимо применить то или иное действие.
Теперь о видах локаторов:
1) id=<element_id> - соответствует элементу, у которого атрибут id равен значению element_id.
Например, у нас есть элемент, который в HTML записывается так:
<input type=text id='some_input_id' name='some_input_name' value='' />
В этом случае локатор будет иметь вид: id=some_input_id. Также следует отметить, что данный вид локаторов является одним из самых быстрых в нахождении и одним из самых уникальных. Это связано с тем, что в DOM-структуре ссылки на элементы, у которых задан ID, хранятся в отдельной таблице и через JScript (собственно именно через него осуществляется доступ к элементам на конечном уровне) обращение к элементам по ID идет достаточно короткой инструкцией, наподобиеsome_input_id.
2) name=<element_name> - соответствует элементу, у которого атрибут name равен значению element_name. Эффективно применяется при работе с полями ввода формы (кнопки, текстовые поля, выпадающие списки). Как правило, значения элементов формы используются в запросах, которые идут на сервер и как раз атрибут name в этих запросах ставит в соответствие поле и его значение. Если брать предыдущий пример:
<input type=text id='some_input_id' name='some_input_name' value='' />
Данный элемент может быть также идентифицирован локатором вида name=some_input_name.
Этот тип локаторов тоже является достаточно быстрым в нахождении, но менее уникальным, так как на странице может быть несколько форм, у которых могут быть элементы с одинаковым именем.
3) link=<link_text> - специально для ссылок используется отдельно зарезервированный тип локаторов, который находит нужную ссылку по ее тексту. Это сделано отчасти потому, что ссылки как правило не имеют таких атрибутов как ID или name. Соответственно, ссылка, которая в HTML записывается так:
<a href='http://some_url'>Link Text 2345</a>
В Selenium идентифицируется локатором link=Link Text 2345.
И небольшой частный случай:
У ссылки есть фиксированная часть и есть часть, которая может варьироваться. Допустим, в предыдущем примере у нас число может варьироваться. В этом случае мы можем использовать wildcards, в частности '*'. Мы можем идентифицировать ссылку локатором вида: link=Link Text*
и данный локатор будет соответствовать первой ссылке, текст которой будет начинаться с 'Link Text'.
4) xpath=<xpath_locator> - наиболее универсальный тип локаторов.
Как XPath формируется - HTML, как и его более обобщенная форма - XML, представляет собой различное сочетание тегов, которые могут содержать вложенные теги, а те в свою очередь тоже могут содержать теги и т.д. То есть ,выстраивается определенная иерархия, наподобие структуры каталогов в файловой системе. И задача XPath - отразить подобный путь к нужному элементу, с учетом иерархии. Например, XPath вида: A/B/C/D указывает на некоторый элемент с тегом D, который находится внутри тега C, а тот в свою очередь - внутри тега B, который находится внутри тега A, который находится на самом верхнем уровне иерархии.
Если брать использование XPath в Selenium, то там зачастую полный путь указывать не нужно, более того - вредно. Особенно если вложенность тега нужного элемента достаточно высока. Как правило, удобно указывать путь, начиная с некоторого промежуточного элемента, пропуская теги более высокого порядка. Например, такой XPath:
//table/tbody/tr/td/a ссылается на первую ссылку в первой строке тела первой таблицы. Обратите внимание на начало данной записи. Строка '//' означает, что поиск элемента начинается с некоторого произвольного места.
Хорошие наглядные примеры тут:
http://www.w3schools.com/XPath/xpath_syntax.asp
http://zvon.org/xxl/XPathTutorial/Output_rus/example1.html
http://internetka.in.ua/xpath-start-part3/
5) css=<css_path> - данный тип локаторов основан на описаниях таблиц стилей (CSS), соответственно и синтаксис такой же. В отличие от локаторов по ID, по имени или по тексту ссылки, данный тип локаторов может учитывать иерархию объектов, а также значения атрибутов, что делает его ближайшим аналогом XPath. А в силу того, что объект находится по данному локатору быстрее, чем XPath, рекомендуется прибегать к помощи CSS вместо XPath. Видео в тему:
Для тренировки и проверки своих локаторов - используем браузер Firefox, а так же плагины к нему:
FireBug - https://addons.mozilla.org/ru/firefox/addon/firebug/
FirePath - https://addons.mozilla.org/ru/firefox/addon/firepath/
После их установки, открываем фаирбаг и переходим на вкладку FirePath. Ниже увидим строку для ввода локатора. Слева от нее можно выбрать вид локатора который мы проверяем - CSS или XPath. Далее заходим на тестовую страничку и пробуем написать свой селектор. Например: тестовая страница http://vk.com В левой верхней части экрана firebug - есть кнопка для исследования элемента. Выглядит как стрелка курсора мыши кликающая на прямоугольник.
Жмем на нее и на поле для ввода "Телефон или email" на тестовой странице vk.com Внизу экрана увидим как firepath нашел нужную строку кода страницы, на которой описан интересующий нас элемент. В данном случае поле для ввода телефона. В строку для ввода локатора он автоматически сгенерировал селектор, по которому мы можем обратиться к данному элементу. Слева внизу мы видим "1 matching node" что говорит сколько элементов имеют такой локатор. Хороший локатор всегда уникален и находит только один нужный нам элемент. Итак. Код искомого нами элемента:
<div class="labeled">
<input id="quick_email" class="text" type="text" name="email"/>
</div>
input - то что нам надо. Как мы можем к нему обратиться:
по частному локатору id:
id='quick_email'
по частному локатору name:
name='email'
по css селектору:
css=input[id='quick_email'] или css=input[name='email']
по xpath:
.//*[@id='quick_email'] или .//*[@name='email']
В данном примере я расположил варианты обращения к данному элементу по их скорости.
findElement - (поиск элемента на странице)
click - (клик по выбранному элементу)
sendKeys - (ввод данных в поле для ввода текста)
select - (выбор значения из выпадающего списка)
Когда мы делаем клик мышкой, вводим текст и выполняем прочие действия на странице - мы эти действия выполняете над вполне конкретным объектом. Selenium WebDriver поступает так же, но поскольку он не умеет читать наши мысли, то ему надо четко указать объект, для которого необходимо применить то или иное действие.
Теперь о видах локаторов:
1) id=<element_id> - соответствует элементу, у которого атрибут id равен значению element_id.
Например, у нас есть элемент, который в HTML записывается так:
<input type=text id='some_input_id' name='some_input_name' value='' />
В этом случае локатор будет иметь вид: id=some_input_id. Также следует отметить, что данный вид локаторов является одним из самых быстрых в нахождении и одним из самых уникальных. Это связано с тем, что в DOM-структуре ссылки на элементы, у которых задан ID, хранятся в отдельной таблице и через JScript (собственно именно через него осуществляется доступ к элементам на конечном уровне) обращение к элементам по ID идет достаточно короткой инструкцией, наподобиеsome_input_id.
2) name=<element_name> - соответствует элементу, у которого атрибут name равен значению element_name. Эффективно применяется при работе с полями ввода формы (кнопки, текстовые поля, выпадающие списки). Как правило, значения элементов формы используются в запросах, которые идут на сервер и как раз атрибут name в этих запросах ставит в соответствие поле и его значение. Если брать предыдущий пример:
<input type=text id='some_input_id' name='some_input_name' value='' />
Данный элемент может быть также идентифицирован локатором вида name=some_input_name.
Этот тип локаторов тоже является достаточно быстрым в нахождении, но менее уникальным, так как на странице может быть несколько форм, у которых могут быть элементы с одинаковым именем.
3) link=<link_text> - специально для ссылок используется отдельно зарезервированный тип локаторов, который находит нужную ссылку по ее тексту. Это сделано отчасти потому, что ссылки как правило не имеют таких атрибутов как ID или name. Соответственно, ссылка, которая в HTML записывается так:
<a href='http://some_url'>Link Text 2345</a>
В Selenium идентифицируется локатором link=Link Text 2345.
И небольшой частный случай:
У ссылки есть фиксированная часть и есть часть, которая может варьироваться. Допустим, в предыдущем примере у нас число может варьироваться. В этом случае мы можем использовать wildcards, в частности '*'. Мы можем идентифицировать ссылку локатором вида: link=Link Text*
и данный локатор будет соответствовать первой ссылке, текст которой будет начинаться с 'Link Text'.
4) xpath=<xpath_locator> - наиболее универсальный тип локаторов.
Как XPath формируется - HTML, как и его более обобщенная форма - XML, представляет собой различное сочетание тегов, которые могут содержать вложенные теги, а те в свою очередь тоже могут содержать теги и т.д. То есть ,выстраивается определенная иерархия, наподобие структуры каталогов в файловой системе. И задача XPath - отразить подобный путь к нужному элементу, с учетом иерархии. Например, XPath вида: A/B/C/D указывает на некоторый элемент с тегом D, который находится внутри тега C, а тот в свою очередь - внутри тега B, который находится внутри тега A, который находится на самом верхнем уровне иерархии.
Если брать использование XPath в Selenium, то там зачастую полный путь указывать не нужно, более того - вредно. Особенно если вложенность тега нужного элемента достаточно высока. Как правило, удобно указывать путь, начиная с некоторого промежуточного элемента, пропуская теги более высокого порядка. Например, такой XPath:
//table/tbody/tr/td/a ссылается на первую ссылку в первой строке тела первой таблицы. Обратите внимание на начало данной записи. Строка '//' означает, что поиск элемента начинается с некоторого произвольного места.
Хорошие наглядные примеры тут:
http://www.w3schools.com/XPath/xpath_syntax.asp
http://zvon.org/xxl/XPathTutorial/Output_rus/example1.html
http://internetka.in.ua/xpath-start-part3/
5) css=<css_path> - данный тип локаторов основан на описаниях таблиц стилей (CSS), соответственно и синтаксис такой же. В отличие от локаторов по ID, по имени или по тексту ссылки, данный тип локаторов может учитывать иерархию объектов, а также значения атрибутов, что делает его ближайшим аналогом XPath. А в силу того, что объект находится по данному локатору быстрее, чем XPath, рекомендуется прибегать к помощи CSS вместо XPath. Видео в тему:
FireBug - https://addons.mozilla.org/ru/firefox/addon/firebug/
FirePath - https://addons.mozilla.org/ru/firefox/addon/firepath/
После их установки, открываем фаирбаг и переходим на вкладку FirePath. Ниже увидим строку для ввода локатора. Слева от нее можно выбрать вид локатора который мы проверяем - CSS или XPath. Далее заходим на тестовую страничку и пробуем написать свой селектор. Например: тестовая страница http://vk.com В левой верхней части экрана firebug - есть кнопка для исследования элемента. Выглядит как стрелка курсора мыши кликающая на прямоугольник.
Жмем на нее и на поле для ввода "Телефон или email" на тестовой странице vk.com Внизу экрана увидим как firepath нашел нужную строку кода страницы, на которой описан интересующий нас элемент. В данном случае поле для ввода телефона. В строку для ввода локатора он автоматически сгенерировал селектор, по которому мы можем обратиться к данному элементу. Слева внизу мы видим "1 matching node" что говорит сколько элементов имеют такой локатор. Хороший локатор всегда уникален и находит только один нужный нам элемент. Итак. Код искомого нами элемента:
<div class="labeled">
<input id="quick_email" class="text" type="text" name="email"/>
</div>
input - то что нам надо. Как мы можем к нему обратиться:
по частному локатору id:
id='quick_email'
по частному локатору name:
name='email'
по css селектору:
css=input[id='quick_email'] или css=input[name='email']
по xpath:
.//*[@id='quick_email'] или .//*[@name='email']
В данном примере я расположил варианты обращения к данному элементу по их скорости.
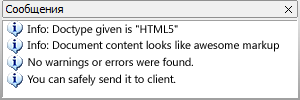 Вы PM. Как узнать – готова ли вёрстка к реальному использованию?
Вы PM. Как узнать – готова ли вёрстка к реальному использованию? Расположение блоков должно быть 1:1 по сравнению с макетом. Допускается расхождение до 5px для текста. Разрешены и даже приветствуются правки размеров и расположения криво нарисованных блоков (разница размерах в 1-2px на разных страницах).
Расположение блоков должно быть 1:1 по сравнению с макетом. Допускается расхождение до 5px для текста. Разрешены и даже приветствуются правки размеров и расположения криво нарисованных блоков (разница размерах в 1-2px на разных страницах).


 Титулка должна быть валидна в любом случае. Ошибки на внутряках простительны в следующих случаях:
Титулка должна быть валидна в любом случае. Ошибки на внутряках простительны в следующих случаях: CSS валидируется по версии 3.0, его валидность не требуется (да и валидатор ещё кривоват), а вот синтаксические ошибки (типа margin: 10xp) исправлять надо.
CSS валидируется по версии 3.0, его валидность не требуется (да и валидатор ещё кривоват), а вот синтаксические ошибки (типа margin: 10xp) исправлять надо.
 В идеале вёрстка должна соответствовать стандарту доступности: WCAG.
В идеале вёрстка должна соответствовать стандарту доступности: WCAG. Проверяется в FF через плагин
Проверяется в FF через плагин 
 Проверяется в FF через плагин
Проверяется в FF через плагин 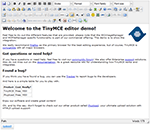 Вёрстка должна тянутся, не разваливаться и не терять дизайнерский вид при изменении контента на странице. Его может быть больше или меньше чем на макете, он может быть обёрнут во всякие
Вёрстка должна тянутся, не разваливаться и не терять дизайнерский вид при изменении контента на странице. Его может быть больше или меньше чем на макете, он может быть обёрнут во всякие
 CSS3 border-radius, gradient, box-shadow, text-shadow вместо использования графики;
CSS3 border-radius, gradient, box-shadow, text-shadow вместо использования графики; Если альтернативные шрифты не прописаны, то у пользователей у которых отсутствует используемый в вёрстке шрифт, вместо него отобразится стандартный. Это может быть не только некрасиво, но и даже поломать отображение сайта.
Если альтернативные шрифты не прописаны, то у пользователей у которых отсутствует используемый в вёрстке шрифт, вместо него отобразится стандартный. Это может быть не только некрасиво, но и даже поломать отображение сайта. Надписи (особенно логотип и главное меню сайта) должны оставаться читабельными, у всех информационных картинок должны быть подписи аккуратным небольшим серым шрифтом (да, для img можно задавать font – это внешний вид alt-текста, что выводится вместо картинки).
Надписи (особенно логотип и главное меню сайта) должны оставаться читабельными, у всех информационных картинок должны быть подписи аккуратным небольшим серым шрифтом (да, для img можно задавать font – это внешний вид alt-текста, что выводится вместо картинки).
 Пожалуй единственный пункт, где нельзя дать чётких критериев. Про то, что такое плохо можно почитать в моей статье «
Пожалуй единственный пункт, где нельзя дать чётких критериев. Про то, что такое плохо можно почитать в моей статье « Это забота о семантичности кода, заголовки структурируют сайт, делают его корректным документом. Корректный Document Outline важен для SEO.
Это забота о семантичности кода, заголовки структурируют сайт, делают его корректным документом. Корректный Document Outline важен для SEO. JS может быть выключен согласно корпоративных требований безопастности. А в Opera Mini он работает только методом перезагрузки страницы.
JS может быть выключен согласно корпоративных требований безопастности. А в Opera Mini он работает только методом перезагрузки страницы. В идеале весь критически важный функционал сайта был доступен без Flash. В реальной жизни нужно:
В идеале весь критически важный функционал сайта был доступен без Flash. В реальной жизни нужно: Проверяется в FF:
Проверяется в FF:

{kind=link}